
When I was a brand-new PhD student, full of innocence and optimism, I loved solving bugs. I loved the challenge of it and the rush I felt when I succeeded. I knew that if I threw all of my energy at a bug, I could solve it in two days, three days tops. I was full of confidence and hope. I had absolutely no idea what I was in for.
Now I am in the final days of my PhD, slightly jaded and a bit cynical, and I still love solving bugs. I love slowly untangling the long chain of cause and effect that is making my model do something weird. I love methodically ruling out possible sources of the problem until I eventually have a breakthrough. I am still full of confidence and hope. But it’s been a long road for me to come around full circle like this.
As part of my PhD, I took a long journey into the world of model coupling. This basically consisted of taking an ocean model and a sea ice model and bashing them together until they got along. The coupling code had already been written by the Norwegian Meteorological Institute for Arctic domains, but it was my job to adapt the model for an Antarctic domain with ice shelf cavities, and to help the master development team find and fix any problems in their beta code. The goal was to develop a model configuration that was sufficiently realistic for published simulations, to help us understand processes on the Antarctic continental shelf and in ice shelf cavities. Spoiler alert, I succeeded. (Paper #1! Paper #2!) But this outcome was far from obvious for most of my PhD. I spent about two and a half years gripped by the fear that my model would never be good enough, that I would never have any publishable results, that my entire PhD would be a failure, etc., etc. My wonderful supervisor insisted that she had absolute confidence in my success at every step along the way. I was afraid to believe her.
Model coupling is a shitfight, and anyone who tells you otherwise has never tried it. There is a big difference between a model that compiles and runs with no errors, and a model that produces results in the same galaxy as reality. For quite a while my model output did seem to be from another galaxy. Transport through Drake Passage – how we measure the strongest ocean current in the world – was going backwards. In a few model cells near the Antarctic coast, sea ice grew and grew and grew until it was more than a kilometre thick. Full-depth convection, from the ocean surface to the seafloor, was active through most of the Southern Ocean. Sea ice refused to export from the continental shelf, where it got thicker and thicker and older and older, while completely disappearing offshore.
How did I fix these bugs? Slowly. Carefully. Methodically. And once in a while, frantically trying everything I could think of at the same time, flailing in all directions. (Sometimes this works! But not usually.) My colleagues (who seem to regard me as The Fixer of Bugs) sometimes ask what my strategy is, if there is a fixed framework they can follow to solve bugs of their own. But I don’t really have a strategy. It’s different every time.
It’s very hard to switch off from model development, as the bugs sit in the back of your brain and follow you around day and night. Sometimes this constant, low-level mulling-over is helpful – the solutions to several bugs have come to me while in the shower, or walking to the shops, or sitting in a lecture theatre waiting for a seminar to start. But usually bug-brain just gets in the way and prevents you from fully relaxing. I remember one night when I didn’t sleep a wink because every time I closed my eyes all I could see were contour plots of sea ice concentration. Another day, at the pub with my colleagues to celebrate a friend’s PhD submission, I stirred my mojito with a straw and thought about stratification of Southern Ocean water masses.
***
When you spend all your time working towards a goal, you start to glorify the way you will feel when that goal is reached. The Day When This Bug Is Fixed. Or even better, The Day When All The Bugs Are Fixed. The clouds will part, and the angels will sing, and the happiness you feel will far outweigh all the strife and struggle it took to get there.
I’m going to spoil it for you: that’s not how it feels. That is just a fiction we tell ourselves to get through the difficult days. When my model was finally “good enough”, I didn’t really feel anything. It’s like when your paper is finally accepted after many rounds of peer review and you’re so tired of the whole thing that you’re just happy to see the back of it. Another item checked off the list. Time to move on to the next project. And the nihilism descends.
But here’s the most important thing. I regret nothing. Model development has been painful and difficult and all-consuming, but it’s also one of the most worthwhile and strangely joyful experiences I’ve had in my life. It’s been fantastic for my career, despite the initial dry spell in publications, because it turns out that employers love to hire model developers. And I think I’ve come out of it tough as nails because the stress of assembling a PhD thesis has been downright relaxing in comparison. Most importantly, model development is fun. I can’t say that enough times. Model development is FUN.
***
A few months ago I visited one of our partner labs for the last time. I felt like a celebrity. Now that I had results, everyone wanted to talk to me. “If you would like to arrange a meeting with Kaitlin, please contact her directly,” the group email said, just like if I were a visiting professor.
I had a meeting with a PhD student who was in the second year of a model development project. “How are you doing?” I asked, with a knowing gaze like a war-weary soldier.
“I’m doing okay,” he said bravely. “I’ve started meditating.” So he had reached the meditation stage. That was a bad sign.
“Try not to worry,” I said. “It gets better, and it will all work out somehow in the end. Would you like to hear about the kinds of bugs I was dealing with when I was in my second year?”
I like to think I gave him hope.


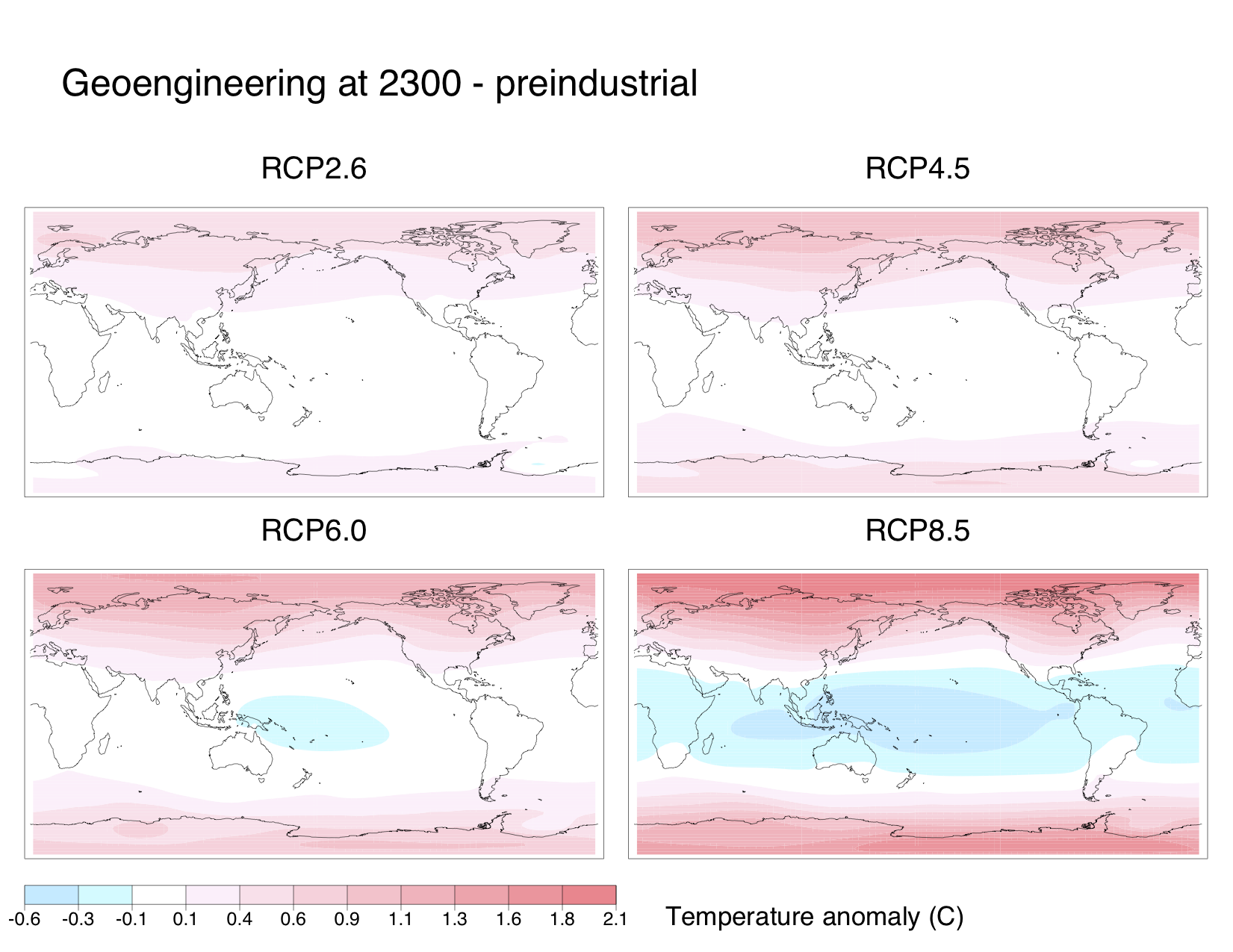

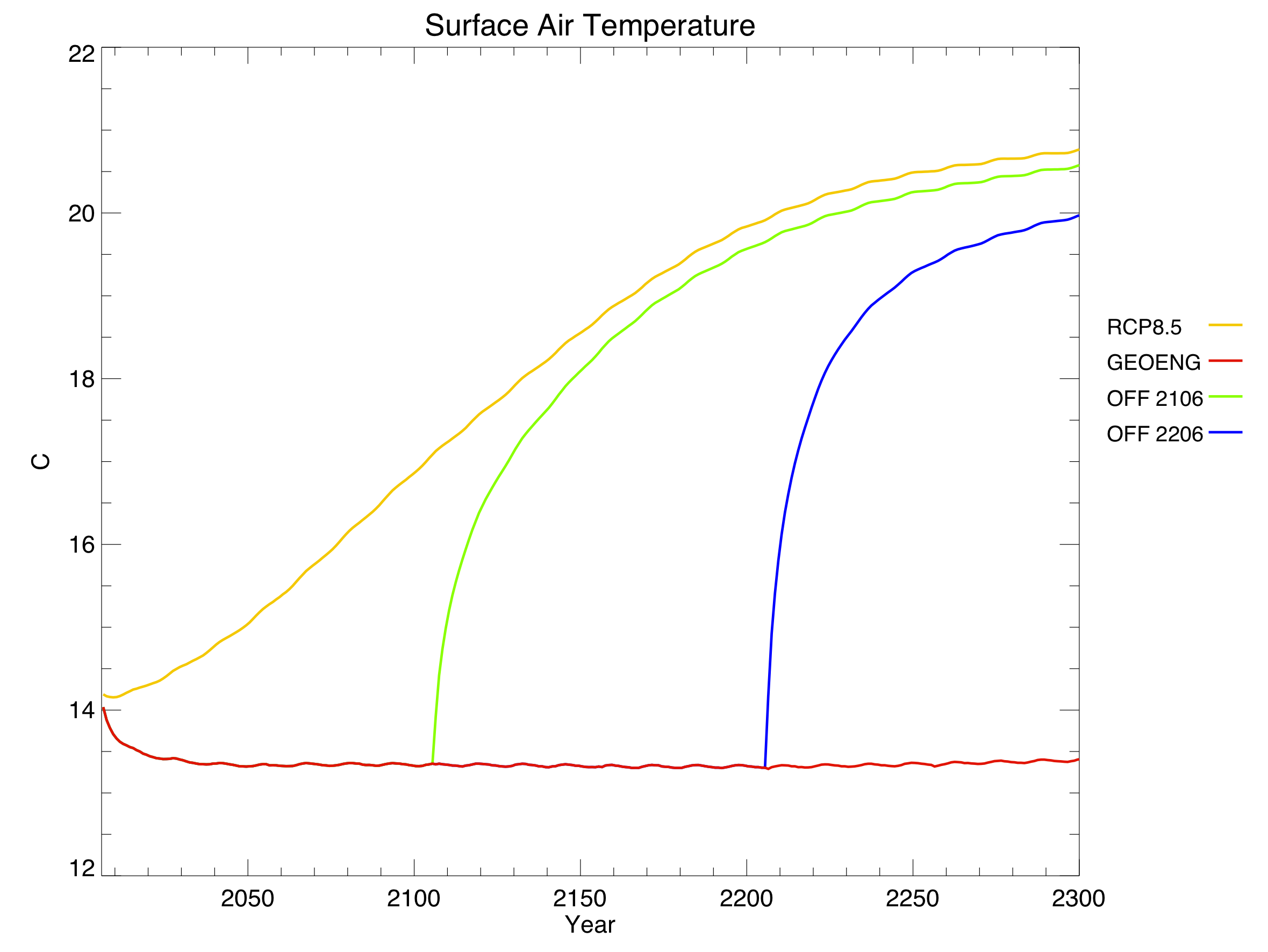
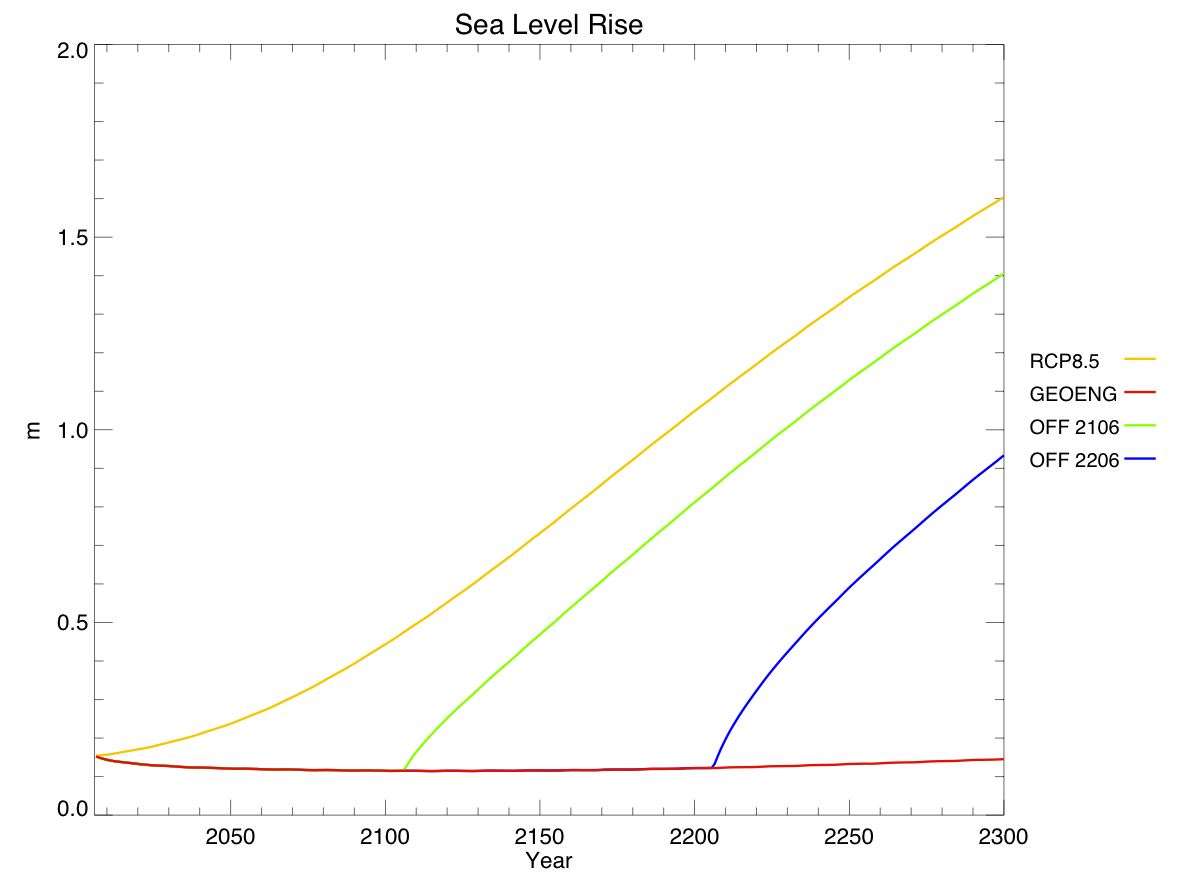
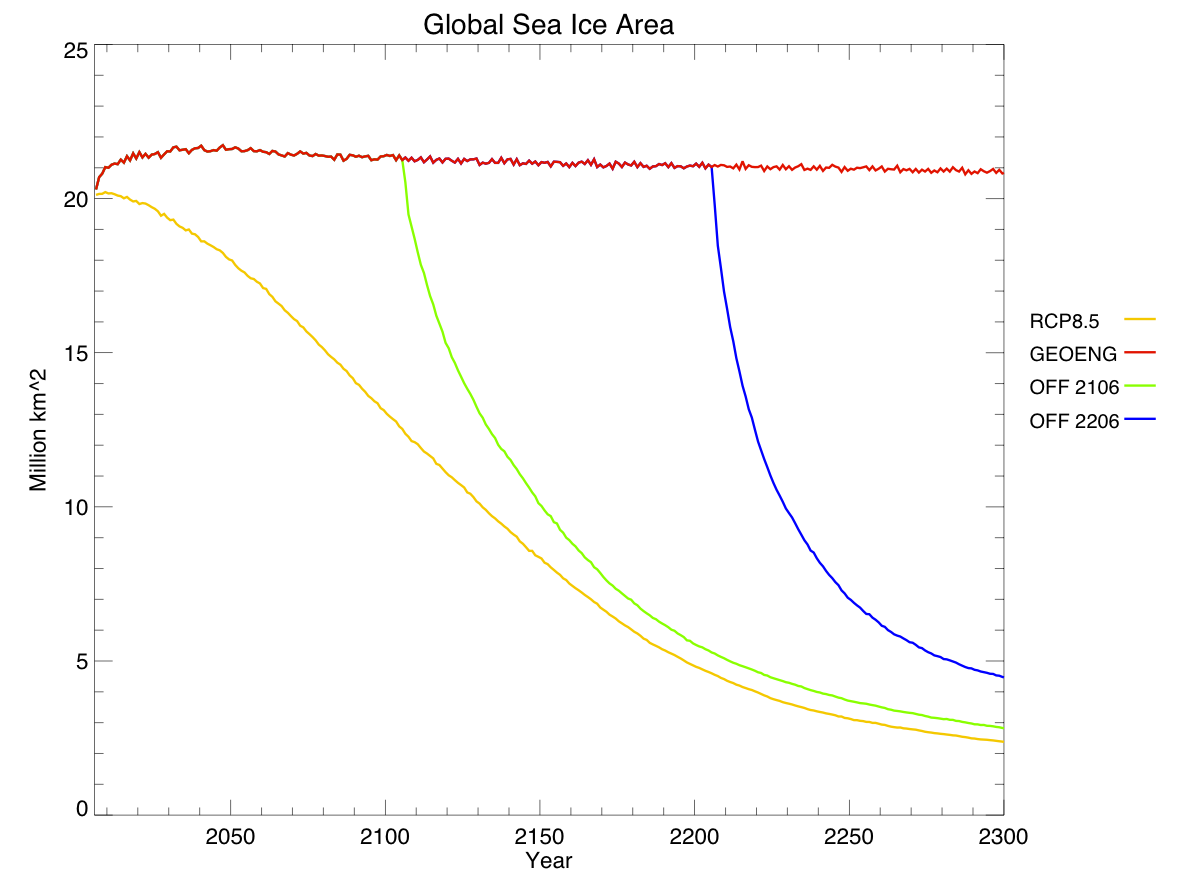

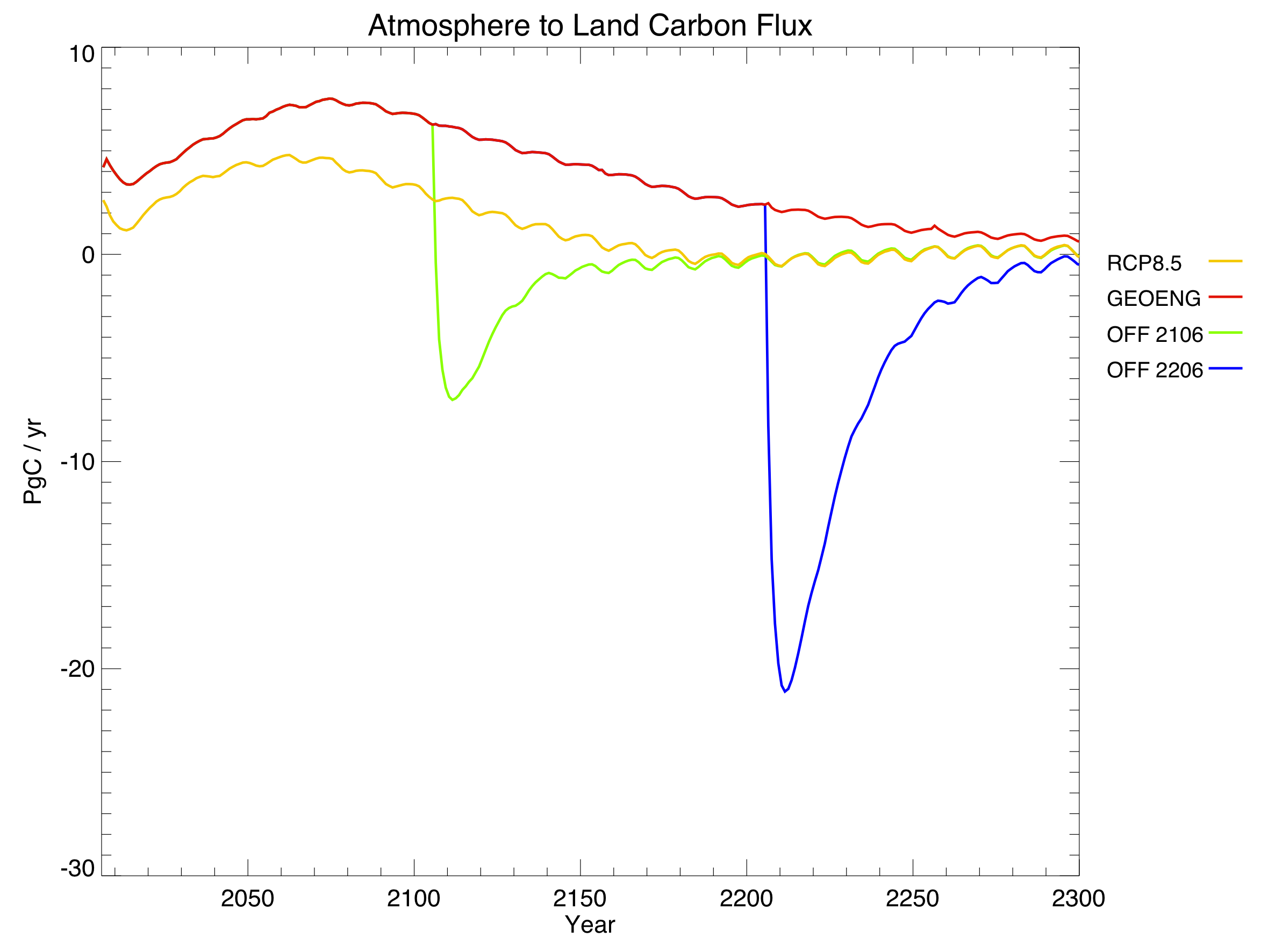
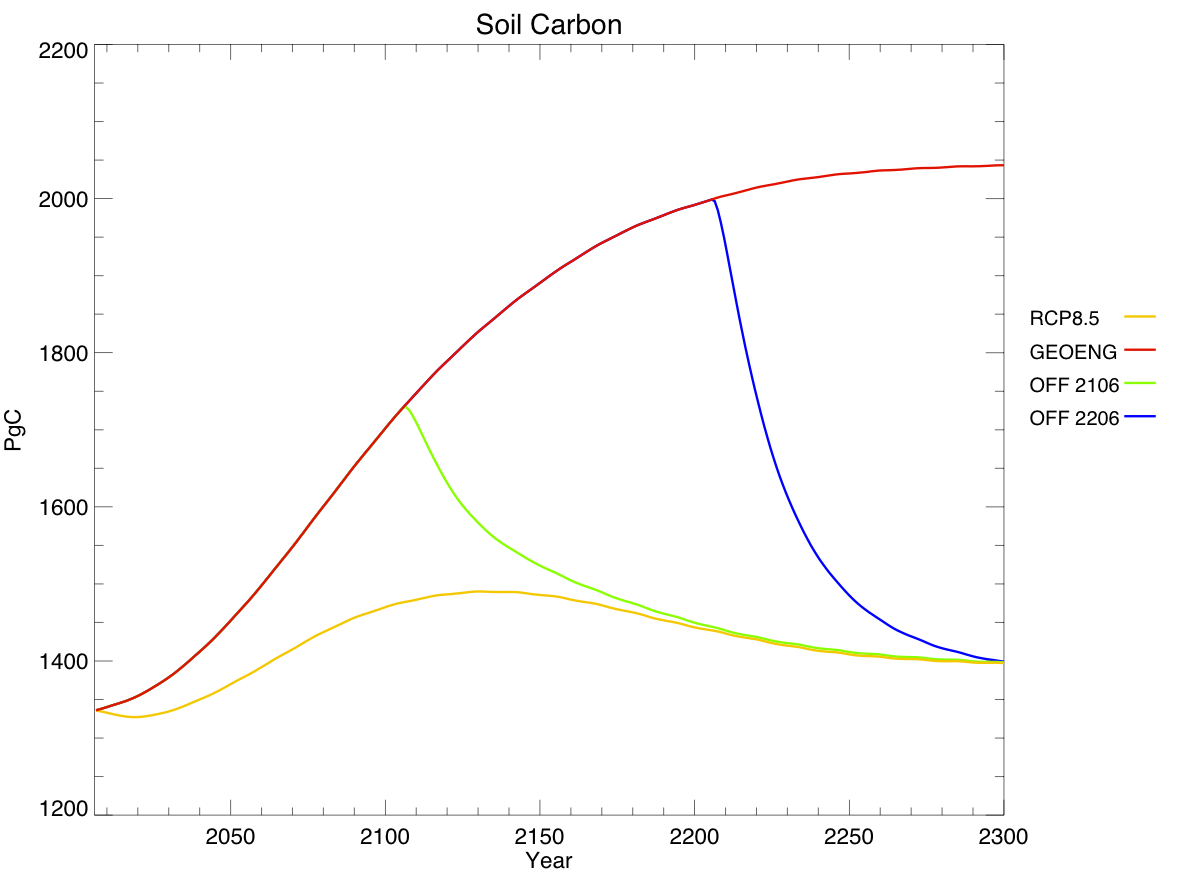
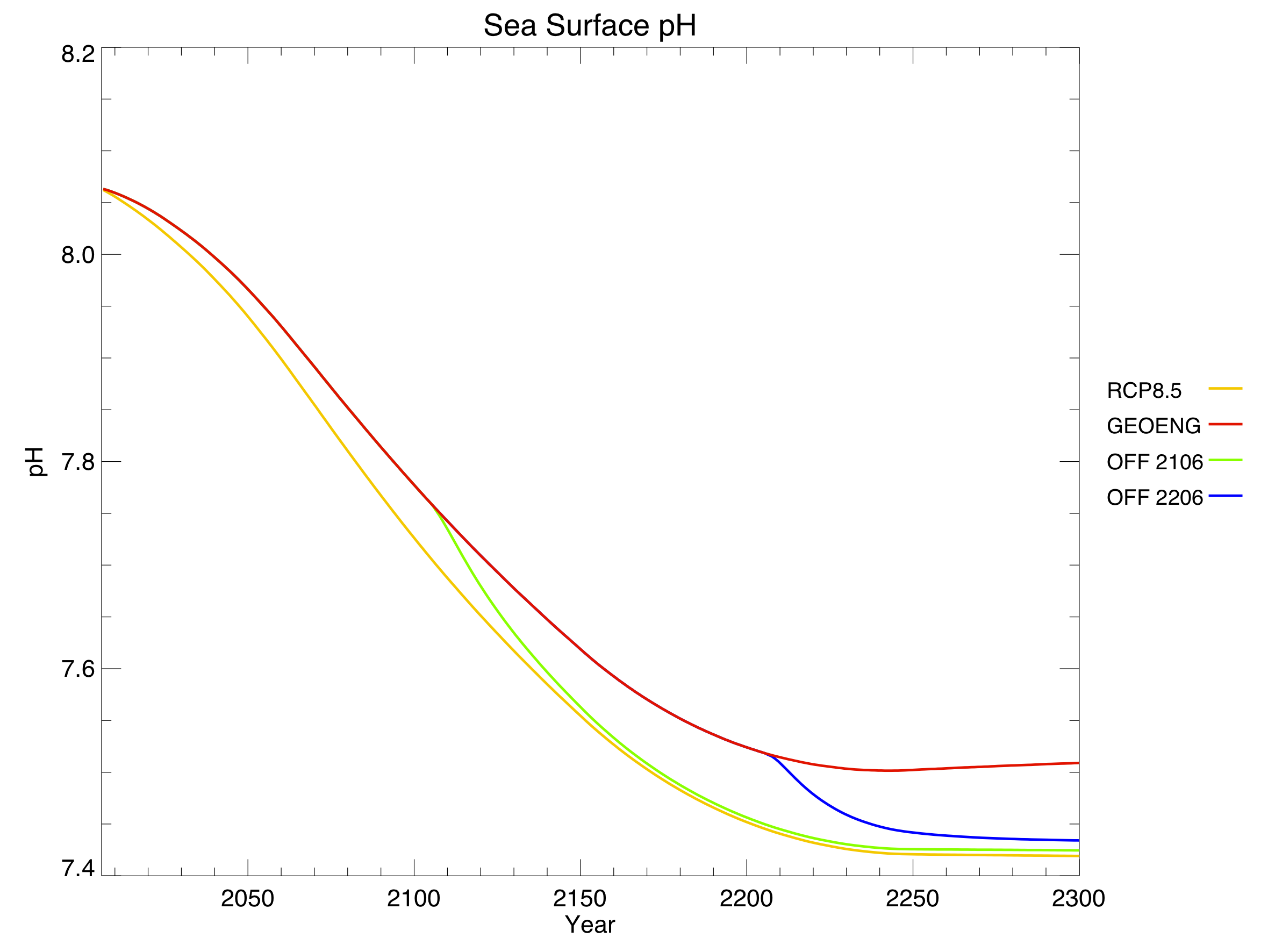




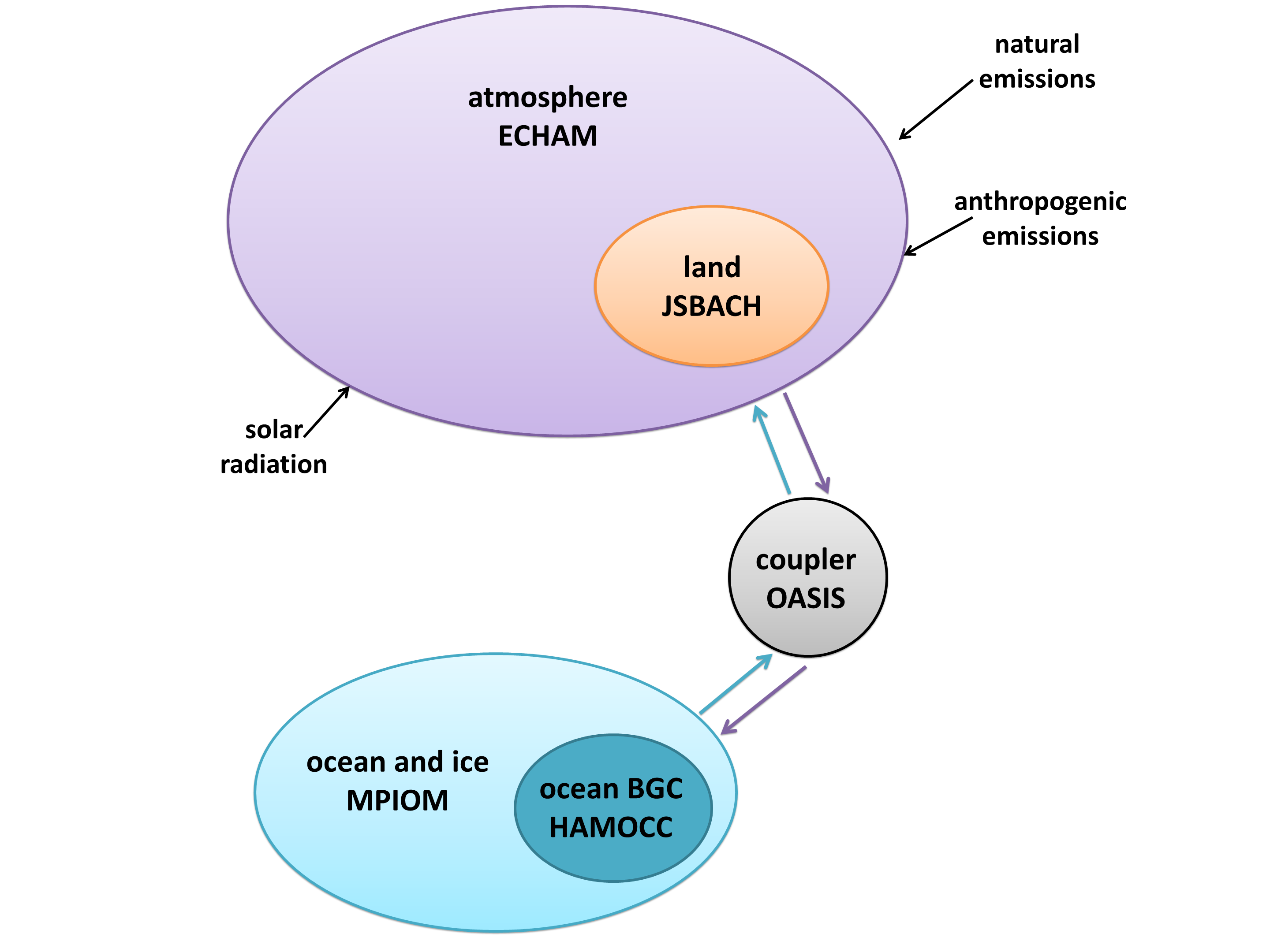
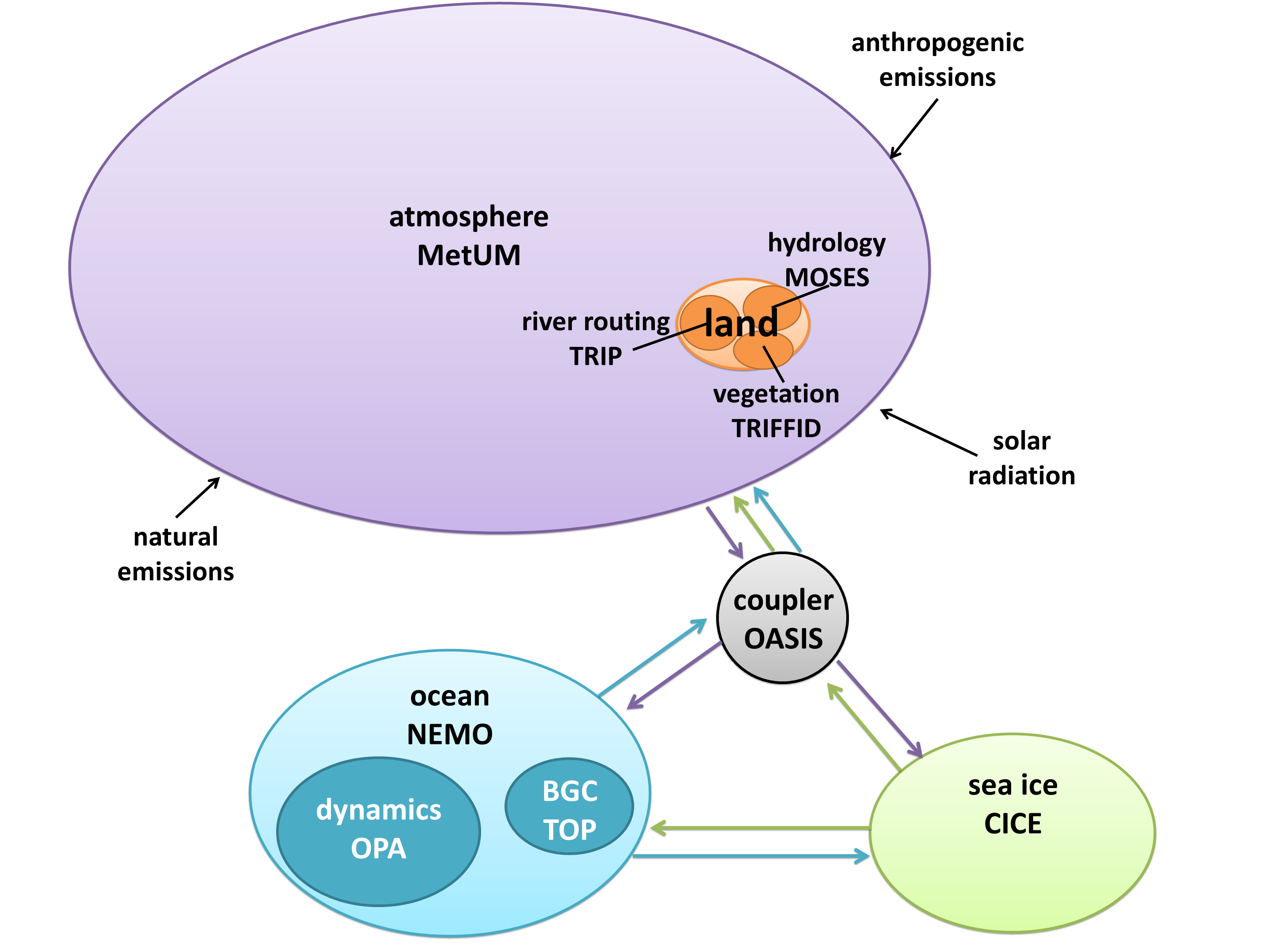
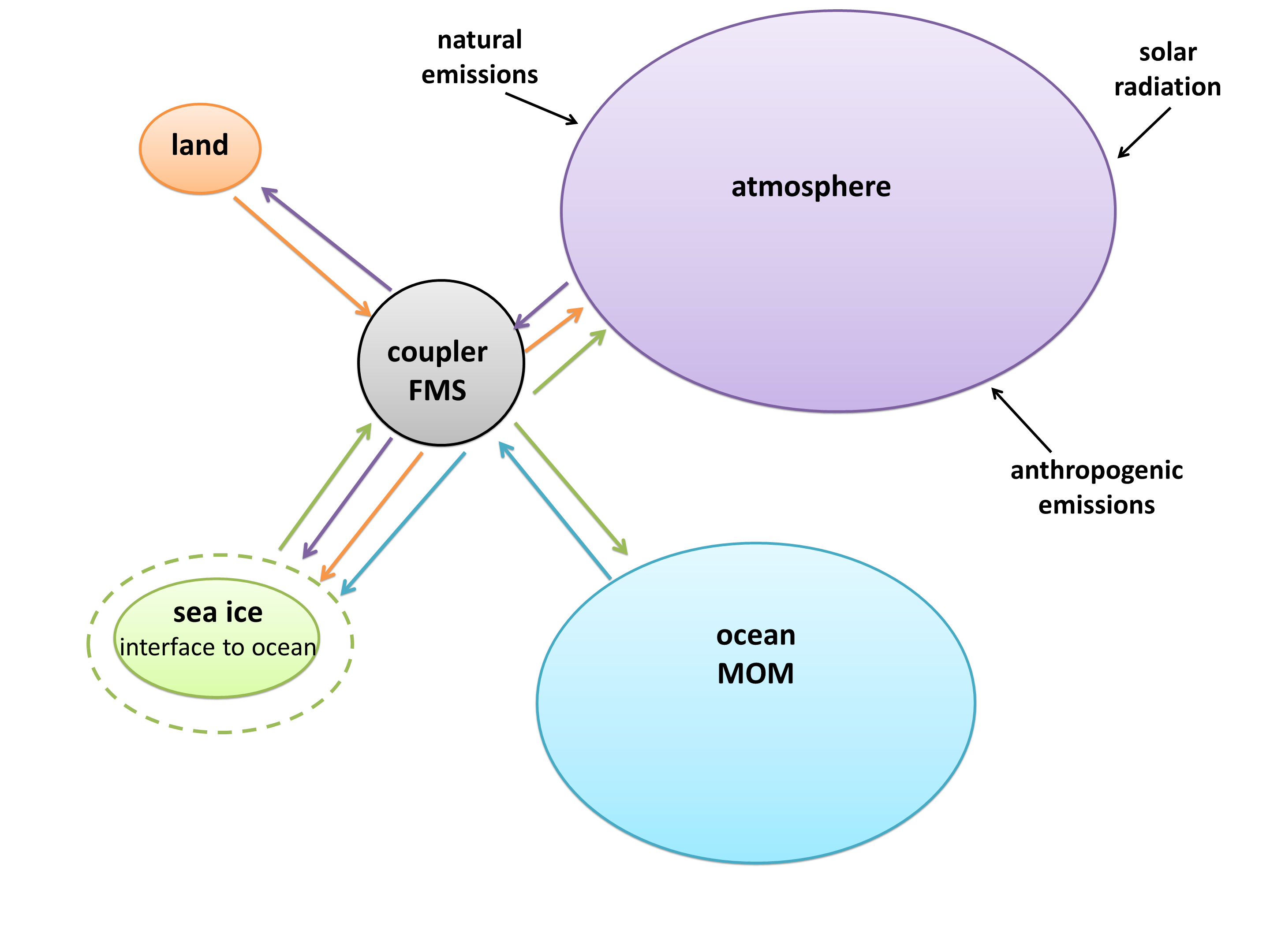
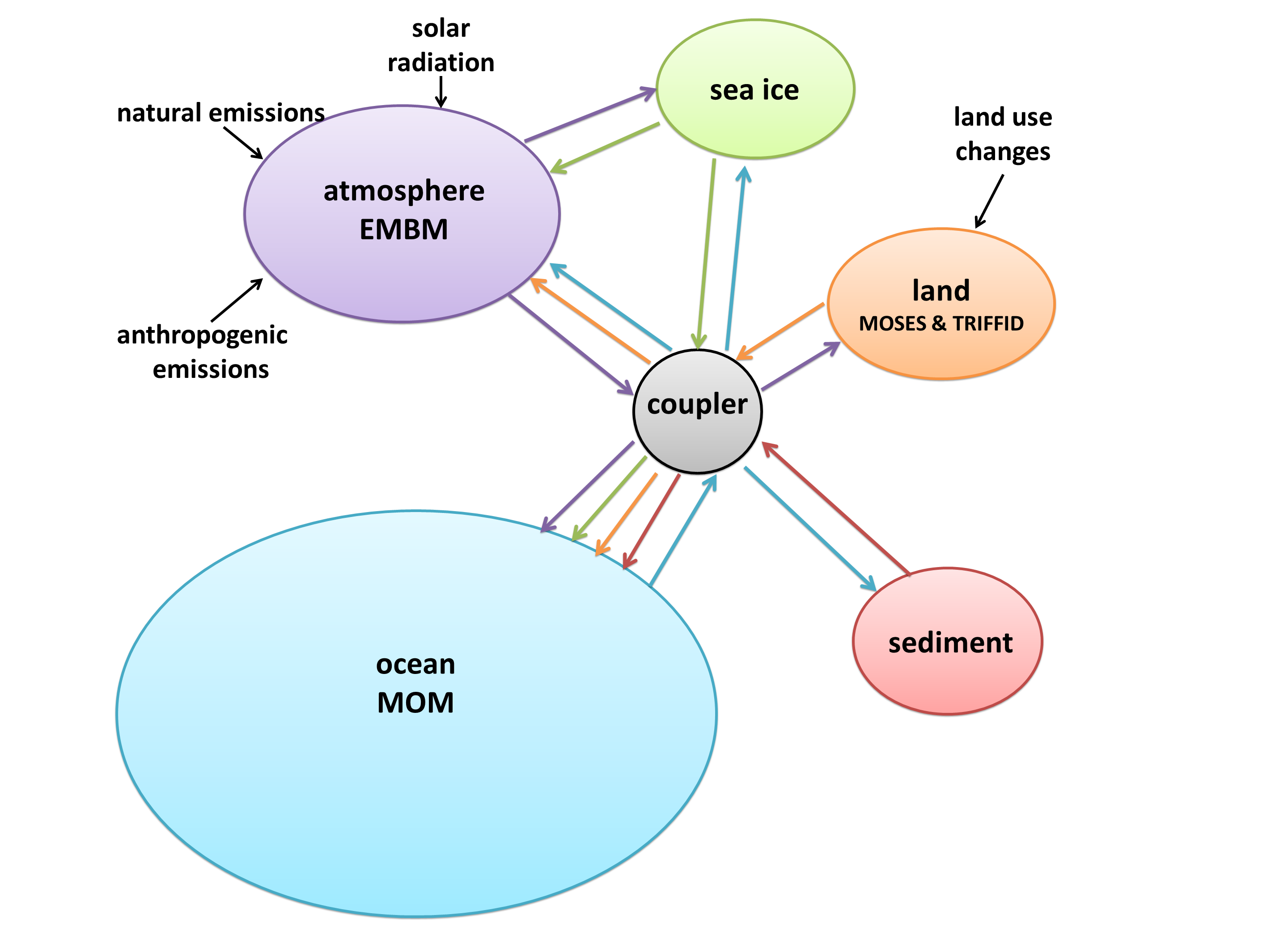
 I created a diagram of each model’s architecture. The area of each bubble is roughly proportional to the lines of code in that component, which we think is a pretty good proxy for complexity – a more complex model will have more subroutines and functions than a simple one. The bubbles are to scale within each model, but not between models, as the total lines of code in a model varies by about a factor of 10. A bit difficult to fit on a poster and still make everything readable! Fluxes from each component are represented by coloured arrows (the same colour as the bubble), and often pass through the coupler before reaching another component.
I created a diagram of each model’s architecture. The area of each bubble is roughly proportional to the lines of code in that component, which we think is a pretty good proxy for complexity – a more complex model will have more subroutines and functions than a simple one. The bubbles are to scale within each model, but not between models, as the total lines of code in a model varies by about a factor of 10. A bit difficult to fit on a poster and still make everything readable! Fluxes from each component are represented by coloured arrows (the same colour as the bubble), and often pass through the coupler before reaching another component.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}