
Climate change will increase ice shelf melt rates around Antarctica. That’s the not-very-surprising conclusion of my latest modelling study, done in collaboration with both Australian and German researchers, which was just published in Journal of Climate. Here’s the less intuitive result: much of the projected increase in melt rates is actually linked to a decrease in sea ice formation.
That’s a lot of different kinds of ice, so let’s back up a bit. Sea ice is just frozen seawater. But ice shelves (as well as ice sheets and icebergs) are originally formed of snow. Snow falls on the Antarctic continent, and over many years compacts into a system of interconnected glaciers that we call an ice sheet. These glaciers flow downhill towards the coast. If they hit the coast and keep going, floating on the ocean surface, the floating bits are called ice shelves. Sometimes the edges of ice shelves will break off and form icebergs, but they don’t really come into this story.
Climate models don’t typically include ice sheets, or ice shelves, or icebergs. This is one reason why projections of sea level rise are so uncertain. But some standalone ocean models do include ice shelves. At least, they include the little pockets of ocean beneath the ice shelves – we call them ice shelf cavities – and can simulate the melting and refreezing that happens on the ice shelf base.
We took one of these ocean/ice-shelf models and forced it with the atmospheric output of regular climate models, which periodically make projections of climate change from now until the end of the century. We completed four different simulations, consisting of two different greenhouse gas emissions scenarios (“Representative Concentration Pathways” or RCPs) and two different choices of climate model (“ACCESS 1.0”, or “MMM” for the multi-model mean). Each simulation required 896 processors on the supercomputer in Canberra. By comparison, your laptop or desktop computer probably has about 4 processors. These are pretty sizable models!
In every simulation, and in every region of Antarctica, ice shelf melting increased over the 21st century. The total increase ranged from 41% to 129% depending on the scenario. The largest increases occurred in the Amundsen Sea region, marked with red circles in the maps below, which happens to be the region exhibiting the most severe melting in recent observations. In the most extreme scenario, ice shelf melting in this region nearly quadrupled.

Percent change in ice shelf melting, caused by the ocean, during the four future projections. The values are shown for all of Antarctica (written on the centre of the continent) as well as split up into eight sectors (colour-coded, written inside the circles). Figure 3 of Naughten et al., 2018, © American Meteorological Society.
So what processes were causing this melting? This is where the sea ice comes in. When sea ice forms, it spits out most of the salt from the seawater (brine rejection), leaving the remaining water saltier than before. Salty water is denser than fresh water, so it sinks. This drives a lot of vertical mixing, and the heat from warmer, deeper water is lost to the atmosphere. The ocean surrounding Antarctica is unusual in that the deep water is generally warmer than the surface water. We call this warm, deep water Circumpolar Deep Water, and it’s currently the biggest threat to the Antarctic Ice Sheet. (I say “warm” – it’s only about 1°C, so you wouldn’t want to go swimming in it, but it’s plenty warm enough to melt ice.)
In our simulations, warming winters caused a decrease in sea ice formation. So there was less brine rejection, causing fresher surface waters, causing less vertical mixing, and the warmth of Circumpolar Deep Water was no longer lost to the atmosphere. As a result, ocean temperatures near the bottom of the Amundsen Sea increased. This better-preserved Circumpolar Deep Water found its way into ice shelf cavities, causing large increases in melting.

Slices through the Amundsen Sea – you’re looking at the ocean sideways, like a slice of birthday cake, so you can see the vertical structure. Temperature is shown on the top row (blue is cold, red is warm); salinity is shown on the bottom row (blue is fresh, red is salty). Conditions at the beginning of the simulation are shown in the left 2 panels, and conditions at the end of the simulation are shown in the right 2 panels. At the beginning of the simulation, notice how the warm, salty Circumpolar Deep Water rises onto the continental shelf from the north (right side of each panel), but it gets cooler and fresher as it travels south (towards the left) due to vertical mixing. At the end of the simulation, the surface water has freshened and the vertical mixing has weakened, so the warmth of the Circumpolar Deep Water is preserved. Figure 8 of Naughten et al., 2018, © American Meteorological Society.
This link between weakened sea ice formation and increased ice shelf melting has troubling implications for sea level rise. The next step is to simulate the sea level rise itself, which requires some model development. Ocean models like the one we used for this study have to assume that ice shelf geometry stays constant, so no matter how much ice shelf melting the model simulates, the ice shelves aren’t allowed to thin or collapse. Basically, this design assumes that any ocean-driven melting is exactly compensated by the flow of the upstream glacier such that ice shelf geometry remains constant.
Of course this is not a good assumption, because we’re observing ice shelves thinning all over the place, and a few have even collapsed. But removing this assumption would necessitate coupling with an ice sheet model, which presents major engineering challenges. We’re working on it – at least ten different research groups around the world – and over the next few years, fully coupled ice-sheet/ocean models should be ready to use for the most reliable sea level rise projections yet.
A modified version of this post appeared on the EGU Cryospheric Sciences Blog.

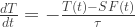



 = E")


- O(t)")
 - \epsilon \sigma T_1(t)^4")
)}{dt} = I(t) - \epsilon \sigma (T_0 + T(t))^4")
 - \epsilon \sigma T_0^4 (1 + \tfrac{T(t)}{T_0})^4")
![c \: \frac{dT}{dt} = I(t) - \epsilon \sigma T_0^4 (1 + 4 \tfrac{T(t)}{T_0} + O[(\tfrac{T(t)}{T_0})^2])](https://s0.wp.com/latex.php?latex=c+%5C%3A+%5Cfrac%7BdT%7D%7Bdt%7D+%3D+I%28t%29+-+%5Cepsilon+%5Csigma+T_0%5E4+%281+%2B+4+%5Ctfrac%7BT%28t%29%7D%7BT_0%7D+%2B+O%5B%28%5Ctfrac%7BT%28t%29%7D%7BT_0%7D%29%5E2%5D%29+&bg=ffffff&fg=333333&s=1 "c \: \frac{dT}{dt} = I(t) - \epsilon \sigma T_0^4 (1 + 4 \tfrac{T(t)}{T_0} + O[(\tfrac{T(t)}{T_0})^2])")
 - \epsilon \sigma T_0^4 (1 + 4 \tfrac{T(t)}{T_0})")
 - \epsilon \sigma T_0^4 - 4 \epsilon \sigma T_0^3 T(t)")
 - O_0 - 4 \epsilon \sigma T_0^3 T(t)")
 - 4 \epsilon \sigma T_0^3 T(t)}{c}")
 - \tfrac{1}{4 \epsilon \sigma T_0^3} F(t)}{\tfrac{c}{4 \epsilon \sigma T_0^3}}")





