Pending examiner approval…soon I will be Dr Kaitlin!


Pending examiner approval…soon I will be Dr Kaitlin!
The DOI system is great and all, and I love being able to access nearly the entire scientific literature without having to leave my desk. But there’s something wonderful about looking up a textbook with no full-text access online, and instead walking down to the uni library with a Dewey decimal number scrawled on a sticky note. Pacing through the shelves of books, finding the one I want, taking it down, and smelling it.
When I was a brand-new PhD student, full of innocence and optimism, I loved solving bugs. I loved the challenge of it and the rush I felt when I succeeded. I knew that if I threw all of my energy at a bug, I could solve it in two days, three days tops. I was full of confidence and hope. I had absolutely no idea what I was in for.
Now I am in the final days of my PhD, slightly jaded and a bit cynical, and I still love solving bugs. I love slowly untangling the long chain of cause and effect that is making my model do something weird. I love methodically ruling out possible sources of the problem until I eventually have a breakthrough. I am still full of confidence and hope. But it’s been a long road for me to come around full circle like this.
As part of my PhD, I took a long journey into the world of model coupling. This basically consisted of taking an ocean model and a sea ice model and bashing them together until they got along. The coupling code had already been written by the Norwegian Meteorological Institute for Arctic domains, but it was my job to adapt the model for an Antarctic domain with ice shelf cavities, and to help the master development team find and fix any problems in their beta code. The goal was to develop a model configuration that was sufficiently realistic for published simulations, to help us understand processes on the Antarctic continental shelf and in ice shelf cavities. Spoiler alert, I succeeded. (Paper #1! Paper #2!) But this outcome was far from obvious for most of my PhD. I spent about two and a half years gripped by the fear that my model would never be good enough, that I would never have any publishable results, that my entire PhD would be a failure, etc., etc. My wonderful supervisor insisted that she had absolute confidence in my success at every step along the way. I was afraid to believe her.
Model coupling is a shitfight, and anyone who tells you otherwise has never tried it. There is a big difference between a model that compiles and runs with no errors, and a model that produces results in the same galaxy as reality. For quite a while my model output did seem to be from another galaxy. Transport through Drake Passage – how we measure the strongest ocean current in the world – was going backwards. In a few model cells near the Antarctic coast, sea ice grew and grew and grew until it was more than a kilometre thick. Full-depth convection, from the ocean surface to the seafloor, was active through most of the Southern Ocean. Sea ice refused to export from the continental shelf, where it got thicker and thicker and older and older, while completely disappearing offshore.
How did I fix these bugs? Slowly. Carefully. Methodically. And once in a while, frantically trying everything I could think of at the same time, flailing in all directions. (Sometimes this works! But not usually.) My colleagues (who seem to regard me as The Fixer of Bugs) sometimes ask what my strategy is, if there is a fixed framework they can follow to solve bugs of their own. But I don’t really have a strategy. It’s different every time.
It’s very hard to switch off from model development, as the bugs sit in the back of your brain and follow you around day and night. Sometimes this constant, low-level mulling-over is helpful – the solutions to several bugs have come to me while in the shower, or walking to the shops, or sitting in a lecture theatre waiting for a seminar to start. But usually bug-brain just gets in the way and prevents you from fully relaxing. I remember one night when I didn’t sleep a wink because every time I closed my eyes all I could see were contour plots of sea ice concentration. Another day, at the pub with my colleagues to celebrate a friend’s PhD submission, I stirred my mojito with a straw and thought about stratification of Southern Ocean water masses.
***
When you spend all your time working towards a goal, you start to glorify the way you will feel when that goal is reached. The Day When This Bug Is Fixed. Or even better, The Day When All The Bugs Are Fixed. The clouds will part, and the angels will sing, and the happiness you feel will far outweigh all the strife and struggle it took to get there.
I’m going to spoil it for you: that’s not how it feels. That is just a fiction we tell ourselves to get through the difficult days. When my model was finally “good enough”, I didn’t really feel anything. It’s like when your paper is finally accepted after many rounds of peer review and you’re so tired of the whole thing that you’re just happy to see the back of it. Another item checked off the list. Time to move on to the next project. And the nihilism descends.
But here’s the most important thing. I regret nothing. Model development has been painful and difficult and all-consuming, but it’s also one of the most worthwhile and strangely joyful experiences I’ve had in my life. It’s been fantastic for my career, despite the initial dry spell in publications, because it turns out that employers love to hire model developers. And I think I’ve come out of it tough as nails because the stress of assembling a PhD thesis has been downright relaxing in comparison. Most importantly, model development is fun. I can’t say that enough times. Model development is FUN.
***
A few months ago I visited one of our partner labs for the last time. I felt like a celebrity. Now that I had results, everyone wanted to talk to me. “If you would like to arrange a meeting with Kaitlin, please contact her directly,” the group email said, just like if I were a visiting professor.
I had a meeting with a PhD student who was in the second year of a model development project. “How are you doing?” I asked, with a knowing gaze like a war-weary soldier.
“I’m doing okay,” he said bravely. “I’ve started meditating.” So he had reached the meditation stage. That was a bad sign.
“Try not to worry,” I said. “It gets better, and it will all work out somehow in the end. Would you like to hear about the kinds of bugs I was dealing with when I was in my second year?”
I like to think I gave him hope.
For many years politicians said, “We’re not even sure climate change is real, so why should we waste money studying it?”
And seemingly overnight, the message has become, “Now that we know climate change is real, we can stop studying it.”
Don’t believe me? This is what Larry Marshall, the chief executive of Australia’s federal science agency CSIRO, wrote in an email to staff earlier this month:
Our climate models are among the best in the world and our measurements honed those models to prove global climate change. That question has been answered, and the new question is what do we do about it, and how can we find solutions for the climate we will be living with?
And then he cut 110 of the 140 climate research jobs in CSIRO’s Oceans and Atmosphere division.
Larry’s statement on its own is perfectly reasonable, but as justification for cutting basic research it is nonsensical. As Andy Pitman, the director of my research centre, responded, “What he fails to realise is that to answer these new questions, you need the same climate scientists!”
Luckily climate scientists are a tough bunch, and we don’t take shit like this lying down.
There’s not very many people in the Southern Hemisphere, and certainly not very many people studying the climate. Australia is really the only Southern Hemisphere country with the critical mass of population and wealth to pull off a significant climate research programme. And historically, Australia has done this very well. I can attest that the climate modelling community is larger and more active in Australia than it is in Canada, despite Canada’s population being about 50% higher.
Some of this research is done in universities, mainly funded by Australian Research Council grants. I’m a part of this system and I love it – we have the freedom to steer our research in whatever direction we think is best, rather than having someone from the government tell us what we can and can’t study. But there isn’t very much stability. Projects are typically funded on a 3-5 year timeline, and with a success rate around 20% for most grant applications, you can never be sure how long a given project will continue. You wouldn’t want to be the official developers of a climate model in an environment like that. You certainly wouldn’t want to be in charge of a massive network of observations. And that is why we need governmental research organisations like CSIRO.
Right now CSIRO hosts the ACCESS model (Australian Community Climate and Earth-System Simulator) which is used by dozens of my friends and colleagues. ACCESS has a good reputation – I particularly like it because it simulates the Southern Ocean more realistically than just about any CMIP5 model. I think this is because it’s pretty much the only contribution to CMIP5 from the Southern Hemisphere. Even if a model is ostensibly “global”, the regions its developers focus on tend to be close to home.
The official ACCESS developers at CSIRO distribute new releases of the code, collect and resolve bug reports, organise submissions to model intercomparison projects like CMIP5, and continually work to improve model efficiency and performance. Some of this work is done in collaboration with the Bureau of Meteorology, the National Computational Infrastructure, the UK Met Office (which provides the atmosphere component of the model), and researchers at Australian universities. But CSIRO is the backbone of ACCESS, and it’s unclear what will happen to the model without its core development team. The Bureau and the universities simply will not be able to pick up the slack.
[It’s] completely understandable that someone who’s spent 20 years, for example, studying climate change, measuring climate change or modelling climate change, it’s perfectly understandable that they don’t want to stop doing that and we must respect that, and we must find a place for them in the rest of the innovation system, perhaps in an university.
–Larry Marshall
In his letter to staff, Larry Marshall wrote that he wants CSIRO to focus on (among other things) “our management of the oceans, climate adaptation, climate interventions (geo-engineering), [and] emergency response to extreme events”. It’s clear that he wants climate research to move away from the question “Are we really, really, really sure that climate change is real?” and more towards “How will climate change impact us and what can we do about it?” Again, I completely agree. But here’s the thing, Larry: We’re already doing that. The research program that you want to eliminate is already evolving into the research program you want to replace it with.
Climate science is evolving in this manner all over the world, not just at CSIRO. Try publishing a paper that concludes “Yes, humans are changing the climate” and see how far you get. Your reviewers will almost certainly respond with “Is that all?” and hit reject. Papers like that were a big deal in the 80s and the 90s. But by now we’ve moved on to more interesting questions.
For example, I’m using ocean models to study how the Southern Ocean might melt the Antarctic Ice Sheet from the bottom up. I’m not doing this to “prove” climate change – how could I even do that in this context? – but to get a better understanding of how much and how fast the sea level will rise over the next few centuries. If we’re going to have to move Miami, Shanghai, New York, and countless other major coastal cities, it would be good to have a few decades’ notice. And we won’t have that kind of notice unless we understand what Antarctica’s doing, through a network of observations (to see what it’s doing right now) and modelling studies (to predict what it might do next).
Without measuring and modelling, our attempts at adaptation and mitigation will be shots in the dark. “The one thing that makes adaptation really difficult is uncertainty,” writes journalist Michael Slezak. “If you don’t know what the climate will be like in the future – whether it will be wetter or dryer, whether cyclones will be more or less frequent – then you can’t prepare. You cannot adapt for a future that you don’t understand.”
Someone’s going to have to convince me that measuring and modelling is far more important than mitigation – and at this point you know, none of my leadership believe that.
–Larry Marshall
My colleagues at CSIRO are having a difficult month. They know that most of them will lose their jobs, or their supervisors will lose their jobs, and that they may have to leave Australia to find another job. But they won’t know who’s staying and who’s going until early March – a full month after the announcement was first made. Due to Larry’s lack of consultation on this decision, the CSIRO staff are reportedly considering industrial action.
The really maddening part of this whole situation is that climate science was specifically targeted. Of the 350 job losses across CSIRO – which studies all kinds of things, not just climate science – 110 were to the climate unit of the Oceans and Atmosphere department, and a similar number to Land and Water. It wouldn’t be so insulting if CSIRO was trimming down a little bit everywhere to cope with its budget cuts. Instead, they’re directly targeting – and essentially eliminating – climate science. “”No one is saying climate change is not important, but surely mitigation, health, education, sustainable industries, and prosperity of the nation are no less important,” Larry wrote in response to mounting criticism. So are we going to cut all of those research programs too?
Climate scientists are rather battle-hardened after so many years of personal attacks by climate change deniers, and everyone jumped into action following CSIRO’s announcement. At the annual meeting of the Australian Meteorological and Oceanographic Society the following week, the attendees organised a bit of a demonstration. It’s not often that the Sydney Morning Herald publishes a photo of “angry scientists”:

(I know just about everyone in this photo. The guy front and centre shares a cubicle with me. Hi Stefan!)
Then scientists from outside Australia started to get involved. The normally-staid World Climate Research Program released an official statement condemning CSIRO’s decision. “Australia will find itself isolated from the community of nations and researchers devoting serious attention to climate change,” they warned.
A few days later an open letter, signed by 2800 climate scientists from almost 60 countries, was sent to the CSIRO and the Australian government. “Without CSIRO’s involvement in both climate measurement and modelling, a significant portion of the Southern Hemisphere oceans and atmosphere will go unmonitored,” the letter warned. You can tell it was written by scientists because it’s complete with references and footnotes, and the signatories are carefully organised both alphabetically and by country.
We’re not sure if our efforts will make any difference. We’ll find out next month whether or not these cuts really will go ahead. Media coverage of this issue has slowed, and there have been no more announcements out of CSIRO. But I suppose we’ve done everything we can.
I feel like the early climate scientists in the ’70s fighting against the oil lobby…I guess I had the realisation that the climate lobby is perhaps more powerful than the energy lobby was back in the ’70s – and the politics of climate I think there’s a lot of emotion in this debate. In fact it almost sounds more like religion than science to me.
–Larry Marshall
Around 55 million years ago, an abrupt global warming event triggered a highly corrosive deep-water current to flow through the North Atlantic Ocean. This process, suggested by new climate model simulations, resolves a long-standing mystery regarding ocean acidification in the deep past.
The rise of CO2 that led to this dramatic acidification occurred during the Paleocene-Eocene Thermal Maximum (PETM), a period when global temperatures rose by around 5°C over several thousand years and one of the largest-ever mass extinctions in the deep ocean occurred.
The PETM, 55 million years ago, is the most recent analogue to present-day climate change that researchers can find. Similarly to the warming we are experiencing today, the PETM warming was a result of increases in atmospheric CO2. The source of this CO2 is unclear, but the most likely explanations include methane released from the seafloor and/or burning peat.
During the PETM, like today, emissions of CO2 were partially absorbed by the ocean. By studying sediment records of the resulting ocean acidification, researchers can estimate the amount of CO2 responsible for warming. However, one of the great mysteries of the PETM has been why ocean acidification was not evenly spread throughout the world’s oceans but was so much worse in the Atlantic than anywhere else.
This pattern has also made it difficult for researchers to assess exactly how much CO2 was added to the atmosphere, causing the 5°C rise in temperatures. This is important for climate researchers as the size of the PETM carbon release goes to the heart of the question of how sensitive global temperatures are to greenhouse gas emissions.
Solving the mystery of these remarkably different patterns of sediment dissolution in different oceans is a vital key to understanding the rapid warming of this period and what it means for our current climate.
A study recently published in Nature Geoscience shows that my co-authors Katrin Meissner, Tim Bralower and I may have cracked this long-standing mystery and revealed the mechanism that led to this uneven ocean acidification.
We now suspect that atmospheric CO2 was not the only contributing factor to the remarkably corrosive Atlantic Ocean during the PETM. Using global climate model simulations that replicated the ocean basins and landmasses of this period, it appears that changes in ocean circulation due to warming played a key role.
55 million years ago, the ocean floor looked quite different than it does today. In particular, there was a ridge on the seafloor between the North and South Atlantic, near the equator. This ridge completely isolated the deep North Atlantic from other oceans, like a giant bathtub on the ocean floor.
In our simulations this “bathtub” was filled with corrosive water, which could easily dissolve calcium carbonate. This corrosive water originated in the Arctic Ocean and sank to the bottom of the Atlantic after mixing with dense salty water from the Tethys Ocean (the precursor to today’s Mediterranean, Black, and Caspian Seas).
Our simulations then reproduced the effects of the PETM as the surface of the Earth warmed in response to increases in CO2. The deep ocean, including the corrosive bottom water, gradually warmed in response. As it warmed it became less dense. Eventually the surface water became denser than the warming deep water and started to sink, causing the corrosive deep water mass to spill over the ridge – overflowing the “giant bath tub”.
The corrosive water then spread southward through the Atlantic, eastward through the Southern Ocean, and into the Pacific, dissolving sediments as it went. It became more diluted as it travelled and so the most severe effects were felt in the South Atlantic. This pattern agrees with sediment records, which show close to 100% dissolution of calcium carbonate in the South Atlantic.
If the acidification event occurred in this manner it has important implications for how strongly the Earth might warm in response to increases in atmospheric CO2.
If the high amount of acidification seen in the Atlantic Ocean had been caused by atmospheric CO2 alone, that would suggest a huge amount of CO2 had to go into the atmosphere to cause 5°C warming. If this were the case, it would mean our climate was not very sensitive to CO2.
But our findings suggest other factors made the Atlantic far more corrosive than the rest of the world’s oceans. This means that sediments in the Atlantic Ocean are not representative of worldwide CO2 concentrations during the PETM.
Comparing computer simulations with reconstructed ocean warming and sediment dissolution during the event, we could narrow our estimate of CO2 release during the event to 7,000 – 10,000 GtC. This is probably similar to the CO2 increase that will occur in the next few centuries if we burn most of the fossil fuels in the ground.
To give this some context, today we are emitting CO2 into the atmosphere at least 10 times faster than than the natural CO2 emissions that caused the PETM. Should we continue to burn fossil fuels at the current rate, we are likely to see the same temperature increase in the space of a few hundred years that took a few thousand years 55 million years ago.
This is an order of magnitude faster and it is likely the impacts from such a dramatic change will be considerably stronger.
Written with the help of my co-authors Katrin and Tim, as well as our lab’s communications manager Alvin Stone.
It turns out that when you submit a paper to a journal like Nature Geoscience “just in case, we have nothing to lose, they’ll probably reject it straight away”…sometimes you are unexpectedly successful.
Assorted media coverage:
More detailed post to come…
Almost four years ago I took a job as a summer student of Dr. Steve Easterbrook, in the software engineering lab of the University of Toronto. This was my first time taking part in research, but also my first time living away from home and my first time using a Unix terminal (both of which are challenging, but immensely rewarding, life skills).
While working with Steve I discovered that climate model output is really pretty (an opinion which hasn’t changed in the four years since) and that climate models are really hard to install (that hasn’t changed either).
At Steve’s suggestion I got a hold of the code for various climate models and started to pick it apart. By the end of the summer I had created a series of standardised diagrams showing the software architecture of each model.
These diagrams proved to be really useful communication tools: we presented our work at AGU the following December, and at NCAR about a year after that, to very positive feedback. Many climate modellers we met at these conferences were pleased to have a software diagram of the model they used (which is very useful to show during presentations), but they were generally more interested in the diagrams for other models, to see how other research groups used different software structures to solve the same problems. “I had no idea they did it like that,” was a remark I heard more than a few times.
Between my undergrad and PhD, I went back to Toronto for a month where I analysed the model code more rigorously. We made a new set of diagrams which was more accurate: the code was sorted into components based on dependency structure, and the area of each component in a given diagram was exactly proportional to the line count of its source code.
Here is the diagram we made for the GFDL-ESM2M model, which is developed at the Geophysical Fluid Dynamics Laboratory in Princeton:

Figure 2 of Alexander et al., 2015
We wrote this all up into a paper, submitted it to GMD, and after several months and several rounds of revision it was published just yesterday! The paper is open access, and can be downloaded for free here. It’s my first paper as lead author which is pretty exciting.
I could go on about all the interesting things we discovered while comparing the diagrams, but that’s all in the paper. Instead I wanted to talk about what’s not in the paper: the story of the long and winding journey we took to get there, from my first day as a nervous summer student in Toronto to the final publication yesterday. These are the stories you don’t read about in scientific papers, which out of necessity detail the methodology as if the authors knew exactly where they were going and got there using the shortest possible path. Science doesn’t often work like that. Science is about messing around and exploring and getting a bit lost and eventually figuring it out and feeling like a superhero when you do. And then writing it up as if it was easy.
I also wanted to express my gratitude to Steve, who has been an amazing source of support, advice, conversations, book recommendations, introductions to scientists, and career advice. I’m so happy that I got to be your student. See you before long on one continent or another!
An ice sheet forms when snow falls on land, compacts into ice, and forms a system of interconnected glaciers which gradually flow downhill like play-dough. In Antarctica, it is so cold that the ice flows right into the ocean before it melts, sometimes hundreds of kilometres from the coast. These giant slabs of ice, floating on the ocean while still attached to the continent, are called ice shelves.
For an ice sheet to have constant size, the mass of ice added from snowfall must equal the mass lost due to melting and calving (when icebergs break off). Since this ice loss mainly occurs at the edges, the rate of ice loss will depend on how fast glaciers can flow towards the edges.
Ice shelves slow down this flow. They hold back the glaciers behind them in what is known as the “buttressing effect”. If the ice shelves were smaller, the glaciers would flow much faster towards the ocean, melting and calving more ice than snowfall inland could replace. This situation is called a “negative mass balance”, which leads directly to global sea level rise.

Respect the ice shelves. They are holding back disaster.
Ice shelves are perhaps the most important part of the Antarctic ice sheet for its overall stability. Unfortunately, they are also the part of the ice sheet most at risk. This is because they are the only bits touching the ocean. And the Antarctic ice sheet is not directly threatened by a warming atmosphere – it is threatened by a warming ocean.
The atmosphere would have to warm outrageously in order to melt the Antarctic ice sheet from the top down. Snowfall tends to be heaviest when temperatures are just below 0°C, but temperatures at the South Pole rarely go above -20°C, even in the summer. So atmospheric warming will likely lead to a slight increase in snowfall over Antarctica, adding to the mass of the ice sheet. Unfortunately, the ocean is warming at the same time. And a slightly warmer ocean will be very good at melting Antarctica from the bottom up.
This is partly because ice melts faster in water than it does in air, even if the air and the water are the same temperature. But the ocean-induced melting will be exacerbated by some unlucky topography: over 40% of the Antarctic ice sheet (by area) rests on bedrock that is below sea level.
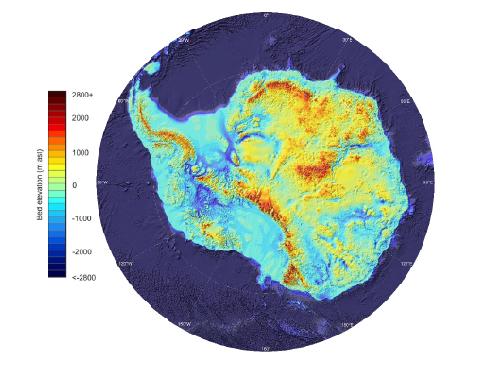
Elevation of the bedrock underlying Antarctica. All of the blue regions are below sea level. (Figure 9 of Fretwell et al.)
This means that ocean water can melt its way in and get right under the ice, and gravity won’t stop it. The grounding lines, where the ice sheet detaches from the bedrock and floats on the ocean as an ice shelf, will retreat. Essentially, a warming ocean will turn more of the Antarctic ice sheet into ice shelves, which the ocean will then melt from the bottom up.
This situation is especially risky on a retrograde bed, where bedrock gets deeper below sea level as you go inland – like a giant, gently sloping bowl. Retrograde beds occur because of isostatic loading (the weight of an ice sheet pushes the crust down, making the tectonic plate sit lower in the mantle) as well as glacial erosion (the ice sheet scrapes away the surface bedrock over time). Ice sheets resting on retrograde beds are inherently unstable, because once the grounding lines reach the edge of the “bowl”, they will eventually retreat all the way to the bottom of the “bowl” even if the ocean water intruding beneath the ice doesn’t get any warmer. This instability occurs because the melting point temperature of water decreases as you go deeper in the ocean, where pressures are higher. In other words, the deeper the ice is in the ocean, the easier it is to melt it. Equivalently, the deeper a grounding line is in the ocean, the easier it is to make it retreat. In a retrograde bed, retreating grounding lines get deeper, so they retreat more easily, which makes them even deeper, and they retreat even more easily, and this goes on and on even if the ocean stops warming.
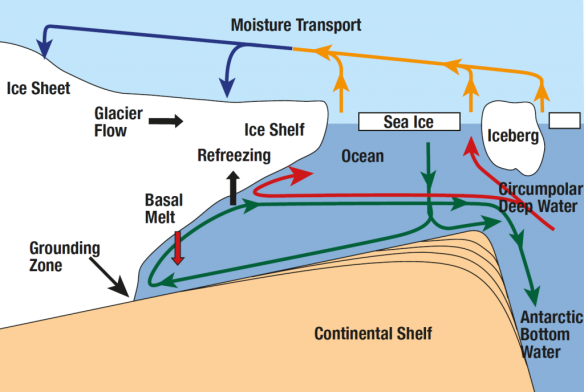
Diagram of an ice shelf on a retrograde bed (“Continental shelf”)
Which brings us to Terrifying Paper #1, by Rignot et al. A decent chunk of West Antarctica, called the Amundsen Sea Sector, is melting particularly quickly. The grounding lines of ice shelves in this region have been rapidly retreating (several kilometres per year), as this paper shows using satellite data. Unfortunately, the Amundsen Sea Sector sits on a retrograde bed, and the grounding lines have now gone past the edge of it. This retrograde bed is so huge that the amount of ice sheet it underpins would cause 1.2 metres of global sea level rise. We’re now committed to losing that ice eventually, even if the ocean stopped warming tomorrow. “Upstream of the 2011 grounding line positions,” Rignot et al., write, “we find no major bed obstacle that would prevent the glaciers from further retreat and draw down the entire basin.”
They look at each source glacier in turn, and it’s pretty bleak:
Only one small glacier, Haynes Glacier, is not necessarily doomed, since there are mountains in the way that cut off the retrograde bed.
From satellite data, you can already see the ice sheet speeding up its flow towards the coast, due to the loss of buttressing as the ice shelves thin: “Ice flow changes are detected hundreds of kilometers inland, to the flanks of the topographic divides, demonstrating that coastal perturbations are felt far inland and propagate rapidly.”
It will probably take a few centuries for the Amundsen Sector to fully disintegrate. But that 1.2 metres of global sea level rise is coming eventually, on top of what we’ve already seen from other glaciers and thermal expansion, and there’s nothing we can do to stop it (short of geoengineering). We’re going to lose a lot of coastal cities because of this glacier system alone.
Terrifying Paper #2, by Mengel & Levermann, examines the Wilkes Basin Sector of East Antarctica. This region contains enough ice to raise global sea level by 3 to 4 metres. Unlike the Amundsen Sector, we aren’t yet committed to losing this ice, but it wouldn’t be too hard to reach that point. The Wilkes Basin glaciers rest on a system of deep troughs in the bedrock. The troughs are currently full of ice, but if seawater got in there, it would melt all the way along the troughs without needing any further ocean warming – like a very bad retrograde bed situation. The entire Wilkes Basin would change from ice sheet to ice shelf, bringing along that 3-4 metres of global sea level rise.
It turns out that the only thing stopping seawater getting in the troughs is a very small bit of ice, equivalent to only 8 centimetres of global sea level rise, which Mengel & Levermann nickname the “ice plug”. As long as the ice plug is there, this sector of the ice sheet is stable; but take the ice plug away, and the whole thing will eventually fall apart even if the ocean stops warming. Simulations from an ice sheet model suggest it would take at least 200 years of increased ocean temperature to melt this ice plug, depending on how much warmer the ocean got. 200 years sounds like a long time for us to find a solution to climate change, but it actually takes much longer than that for the ocean to cool back down after it’s been warmed up.
This might sound like all bad news. And you’re right, it is. But it can always get worse. That means we can always stop it from getting worse. That’s not necessarily good news, but at least it’s empowering. The sea level rise we’re already committed to, whether it’s 1 or 2 or 5 metres, will be awful. But it’s much better than 58 metres, which is what we would get if the entire Antarctic ice sheet melted. Climate change is not an all-or-nothing situation; it falls on a spectrum. We will have to deal with some amount of climate change no matter what. The question of “how much” is for us to decide.
A problem which has plagued oceanography since the very beginning is a lack of observations. We envy atmospheric scientists with their surface stations and satellite data that monitor virtually the entire atmosphere in real time. Until very recently, all that oceanographers had to work with were measurements taken by ships. This data was very sparse in space and time, and was biased towards certain ship tracks and seasons.
A lack of observations makes life difficult for ocean modellers, because there is very little to compare the simulations to. You can’t have confidence in a model if you have no way of knowing how well it’s performing, and you can’t make many improvements to a model without an understanding of its shortcomings.
Our knowledge of the ocean took a giant leap forward in 2000, when a program called Argo began. “Argo floats” are smallish instruments floating around in the ocean that control their own buoyancy, rising and sinking between the surface and about 2000 m depth. They use a CTD sensor to measure Conductivity (from which you can easily calculate salinity), Temperature, and Depth. Every 10 days they surface and send these measurements to a satellite. Argo floats are battery-powered and last for about 4 years before losing power. After this point they are sacrificed to the ocean, because collecting them would be too expensive.
This is what an Argo float looks like while it’s being deployed:

With at least 27 countries helping with deployment, the number of active Argo floats is steadily rising. At the time of this writing, there were 3748 in operation, with good coverage everywhere except in the polar oceans:

The result of this program is a massive amount of high-quality, high-resolution data for temperature and salinity in the surface and intermediate ocean. A resource like this is invaluable for oceanographers, analogous to the global network of weather stations used by atmospheric scientists. It allows us to better understand the current state of the ocean, to monitor trends in temperature and salinity as climate change continues, and to assess the skill of ocean models.
But it’s still not good enough. There are two major shortcomings to Argo floats. First, they can’t withstand the extreme pressure in the deep ocean, so they don’t sink below about 2000 m depth. Since the average depth of the world’s oceans is around 4000 m, the Argo program is only sampling the upper half. Fortunately, a new program called Deep Argo has developed floats which can withstand pressures down to 6000 m depth, covering all but the deepest ocean trenches. Last June, two prototypes were successfully deployed off the coast of New Zealand, and the data collected so far is looking good. If all future Argo floats were of the Deep Argo variety, in five or ten years we would know as much about the deep ocean’s temperature and salinity structure as we currently know about the surface. To oceanographers, particularly those studying bottom water formation and transport, there is almost nothing more exciting than this prospect.
The other major problem with Argo floats is that they can’t handle sea ice. Even if they manage to get underneath the ice by drifting in sideways, the next time they rise to the surface they will bash into the underside of the ice, get stuck, and stay there until their battery dies. This is a major problem for scientists like me who study the Southern Ocean (surrounding Antarctica), which is largely covered with sea ice for much of the year. This ocean will be incredibly important for sea level rise, because the easiest way to destabilise the Antarctic Ice Sheet is to warm up the ocean and melt the ice shelves (the edges of the ice sheet which extend over the ocean) from below. But we can’t monitor this process using Argo data, because there is a big gap in observations over the region. There’s always the manual option – sending in scientists to take measurements – but this is very expensive, and nobody wants to go there in the winter.
Instead, oceanographers have recently teamed up with biologists to try another method of data collection, which is just really excellent:

They are turning seals into Argo floats that can navigate sea ice.

Southern elephant seals swim incredible distances in the Southern Ocean, and often dive as far as 2000 m below the surface. Scientists are utilising the seals’ natural talents to fill in the gaps in the Argo network, so far with great success. Each seal is tranquilized while a miniature CTD is glued to the fur on its head, after which it is released back into the wild. As the seal swims around, the sensors take measurements and communicate with satellites just like regular Argo floats. The next time the seal sheds its coat (once per year), the CTD falls off and the seal gets on with its life, probably wondering what that whole thing was about.
This project is relatively new and it will be a few years before it’s possible to identify trends in the data. It’s also not clear whether or not the seals tend to swim right underneath the ice shelves, where observations would be most useful. But if this dataset gains popularity among oceanographers, and seals become officially integrated into the Argo network…

…then we will be the coolest scientists of all.
After a long hiatus – much longer than I like to think about or admit to – I am finally back. I just finished the last semester of my undergraduate degree, which was by far the busiest few months I’ve ever experienced.
This was largely due to my honours thesis, on which I spent probably three times more effort than was warranted. I built a (not very good, but still interesting) model of ocean circulation and implemented it in Python. It turns out that (surprise, surprise) it’s really hard to get a numerical solution to the Navier-Stokes equations to converge. I now have an enormous amount of respect for ocean models like MOM, POP, and NEMO, which are extremely realistic as well as extremely stable. I also feel like I know the physics governing ocean circulation inside out, which will definitely be useful going forward.
Convocation is not until early June, so I am spending the month of May back in Toronto working with Steve Easterbrook. We are finally finishing up our project on the software architecture of climate models, and writing it up into a paper which we hope to submit early this summer. It’s great to be back in Toronto, and to have a chance to revisit all of the interesting places I found the first time around.
In August I will be returning to Australia to begin a PhD in Climate Science at the University of New South Wales, with Katrin Meissner and Matthew England as my supervisors. I am so, so excited about this. It was a big decision to make but ultimately I’m confident it was the right one, and I can’t wait to see what adventures Australia will bring.
